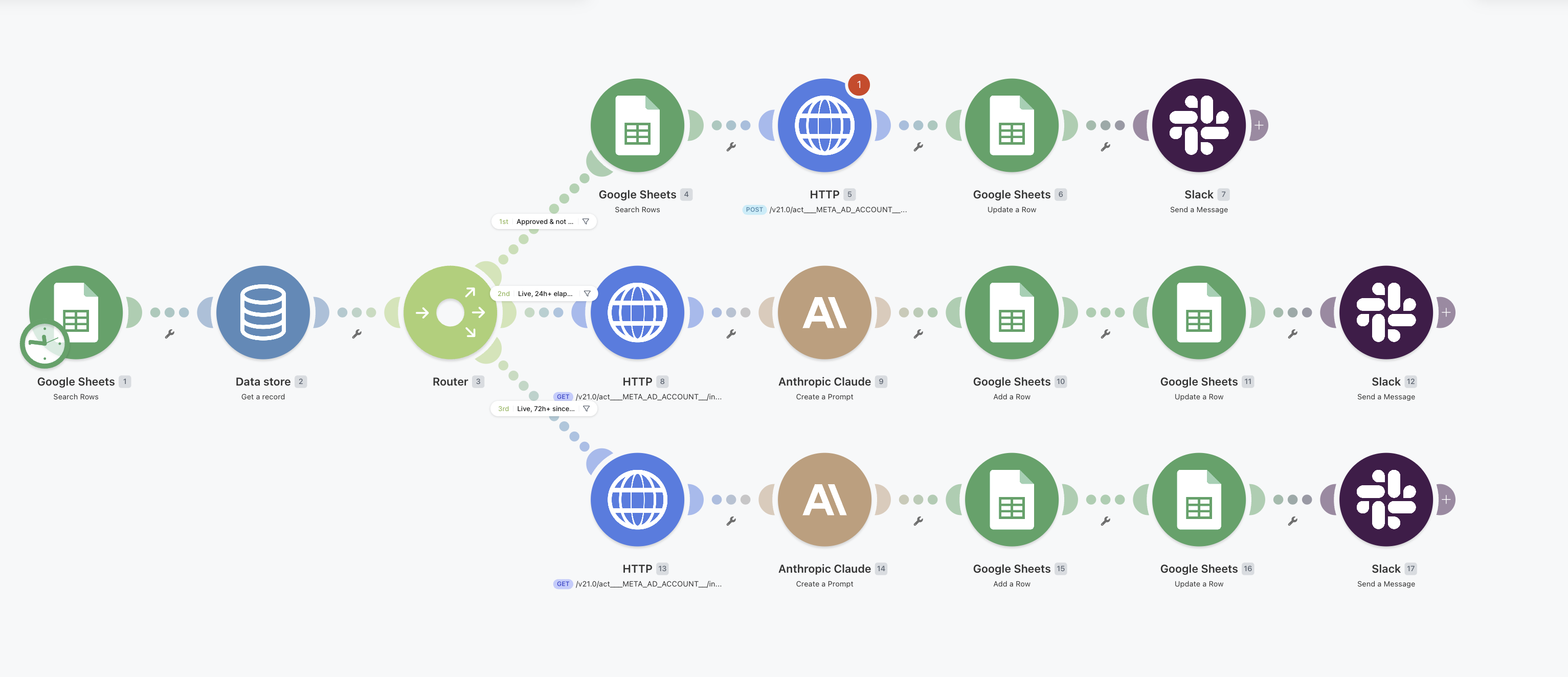
Inside the system
Four scenarios.
One loop that never stops.
Every step is a real Make.com module wired to Google Sheets, a brand-memory data store, Claude, and Slack. Below is exactly what's running — these are the live scenarios, not mockups.
make.com · scenarios · G1
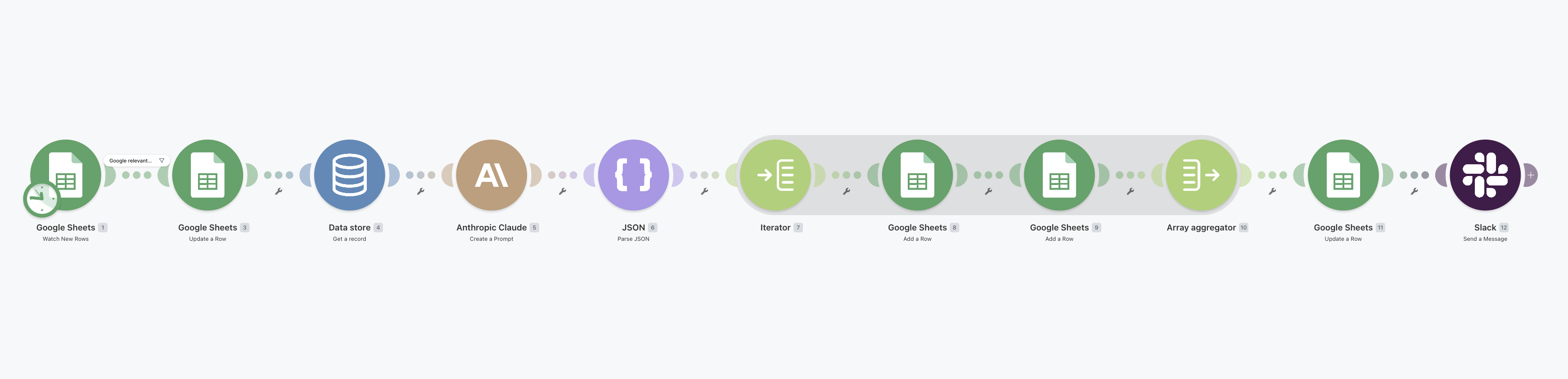
make.com · scenarios · G2
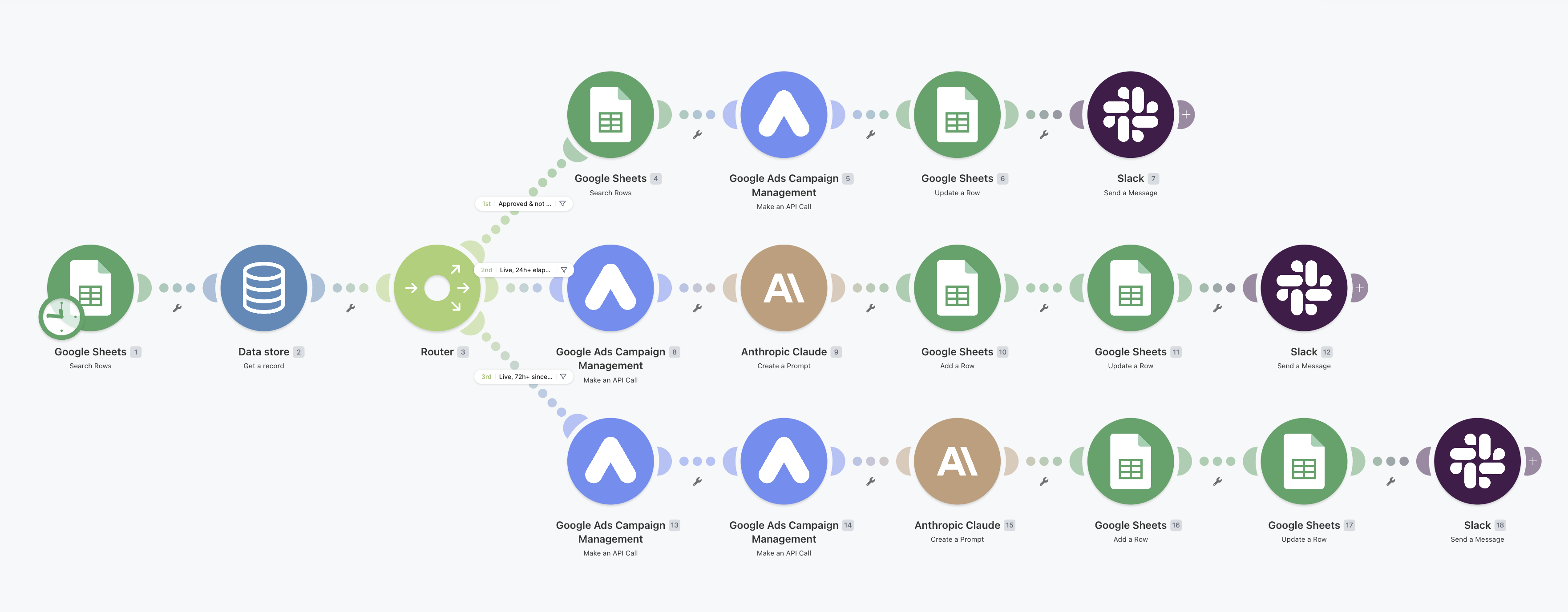
make.com · scenarios · M1
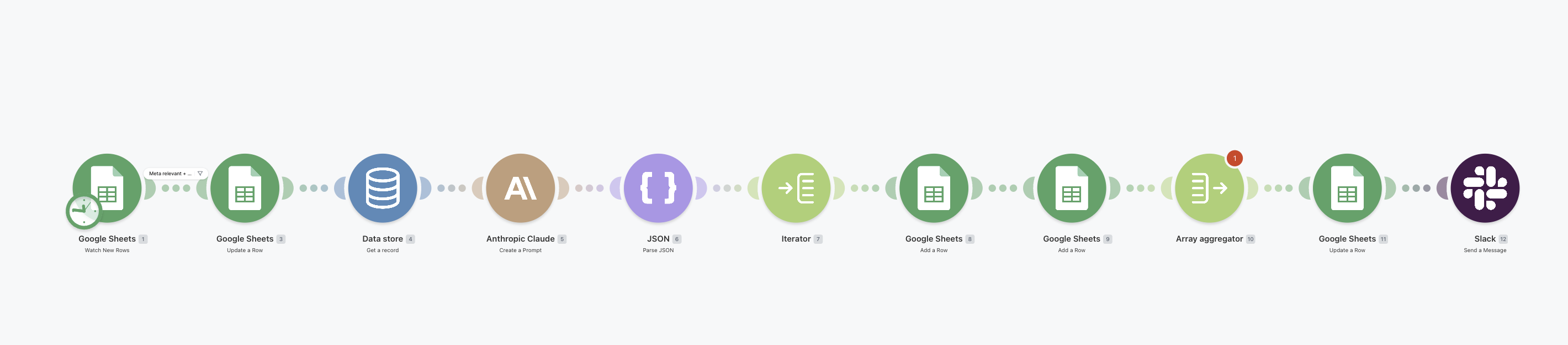
make.com · scenarios · M2